
RecTrees is a large data set of simple 48x48 pixels black and white images of rectlinear tree routings. Rectlinear trees are frequently used in electronics VLSI domains for connecting electronic units (sometimes called Steiner Trees). At post slicon stages, sometimes automatic optical recognition methods are needed to examine defective units. We therefore believe that Neural networks for visual recognition can be very helpful in the chip layout design domain. However, this ipython notebook is intended as basic study unit in the deep leaarning field, that covers simple recognition tasks that can be used in the class room, lab exercises, and in final course projects. At the end of the notebook we will portray a more advanced topics that can be pursued for research and practical applications. As can be seen from the above diagram, these types of images are pretty simple and concise. There are no angles or gray pixels in these images, only black and white pixels, and only straight lines that are either vertical or horizontal. As such, we expect that it would not be hard to devise neural networks that can detect the following feature
- How many terminal vertices a rectree has?
A terminal is simply a point of degree 1 (has only one edge). Sometimes also called a leaf node in graphs theory.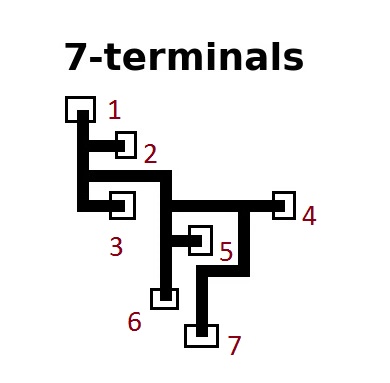
- How many edges the tree has?
- How many corner points a tree has?
A corner is simply a junction point in which two edges meet orthogonally.
The RecTrees database consists of half million black/white 48x48 pixesl images of rectilinear trees. They were generated by an automatic Networkx Python script with random graphs. To make it as simple as possible, we used grayscale 48x48 pixels images, so that it can be processed by standard pc systems with modest computing resources. It is intented to serve as a simple and clean data set for preliminary excursions, tutorials, or course projects in deep learning courses.
It is also intended to serve as a clear and simple minded data set for benchmarking deep learning libraries and deep learning hardware (like GPU systems). As far as we tried within the Keras library, achieving high accuracy prediction scores does require a non-trivial effort and compute time. It is also our hope that this large database of trees can be used for more advanced research on applying deep learning techniques in the VLSI layout domain.
The RecTrees data set consists of 10 HDF5 files, each contains 50000 48x48 pixels grayscale images. So in total, we have 500,000 48x48 grayscale images. We believe that 50K images are sufficient for training (at least for simple tasks as terminals and edge counting). So you may not need to download all the data sets.
- http://www.samyzaf.com/ML/rectrees/rectrees1.h5.zip
- http://www.samyzaf.com/ML/rectrees/rectrees2.h5.zip
- http://www.samyzaf.com/ML/rectrees/rectrees3.h5.zip
- http://www.samyzaf.com/ML/rectrees/rectrees4.h5.zip
- http://www.samyzaf.com/ML/rectrees/rectrees5.h5.zip
- http://www.samyzaf.com/ML/rectrees/rectrees6.h5.zip
- http://www.samyzaf.com/ML/rectrees/rectrees7.h5.zip
- http://www.samyzaf.com/ML/rectrees/rectrees8.h5.zip
- http://www.samyzaf.com/ML/rectrees/rectrees9.h5.zip
- http://www.samyzaf.com/ML/rectrees/rectrees10.h5.zip
Depending on the classification problem you want to solve, you may need to apply some scripts in order to extract a balanced subset from these data sets.
You will need to install the h5py Python module. Reading and writing HDF5 files can be easily learned from the following tutorial: https://www.getdatajoy.com/learn/Read_and_Write_HDF5_from_Python
Some Python utilities for manipulating these data sets can be found here:
http://www.samyzaf.com/cgi-bin/view_file.py?file=ML/rectrees/rectrees.py
This module contains utilities for iterating over the images and graphs within each of
the above HDF5 archives, and utilities for querying or manipulating graphs and trees.
They are base on the Python Networkx module, which you may
need to install before using them.
Prerequisites¶
The code for this IPython notebook was tested on Windows 10, Python 2.7 with keras, numpy, matplotlib and jupyter. The deep learning hardware we used was an NVIDIA GPU (GeForce GTX950) with cuDNN version 5103. Of course, it can also be run on CPU but it will be significantly slower (not recommended).
To run the code in this notebook, you'll also need to download a few private libraries which we use in other examples of this course:
- http://www.samyzaf.com/cgi-bin/view_file.py?file=ML/lib/kerutils.py
- http://www.samyzaf.com/cgi-bin/view_file.py?file=ML/lib/dlutils.py
- http://www.samyzaf.com/cgi-bin/view_file.py?file=ML/lib/imgutils.py
- http://www.samyzaf.com/cgi-bin/view_file.py?file=ML/lib/progmeter.py
- http://www.samyzaf.com/cgi-bin/view_file.py?file=ML/rectrees/rectrees.py
- http://www.samyzaf.com/cgi-bin/view_file.py?file=ML/style-notebook.css (notebook stylesheet)
Here are the Python modules and basic definitions that we need in this project
from keras.models import Sequential, load_model
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Convolution2D, MaxPooling2D, AveragePooling2D, ZeroPadding2D
from keras.optimizers import SGD
from keras.utils import np_utils
from keras.layers.advanced_activations import SReLU, ELU, LeakyReLU
from keras.utils.visualize_util import plot
import matplotlib.pyplot as plt
import matplotlib.cm
from kerutils import *
from imgutils import *
%matplotlib inline
#classes = range(7,19)
classes = range(0,12)
class_name = dict((i, '%d-terminals' % (7+i,)) for i in classes)
nb_classes = len(class_name)
# These are css/html styles for good looking ipython notebooks
from IPython.core.display import HTML
css = open('style-notebook.css').read()
HTML('<style>{}</style>'.format(css));
Terminals Counting Challenge¶
A simple example to start with is to build a neural network for recognizing the number of terminals. The network accepts as inputs 48x48 images of rectilinear trees and outputs their terminal numbers.
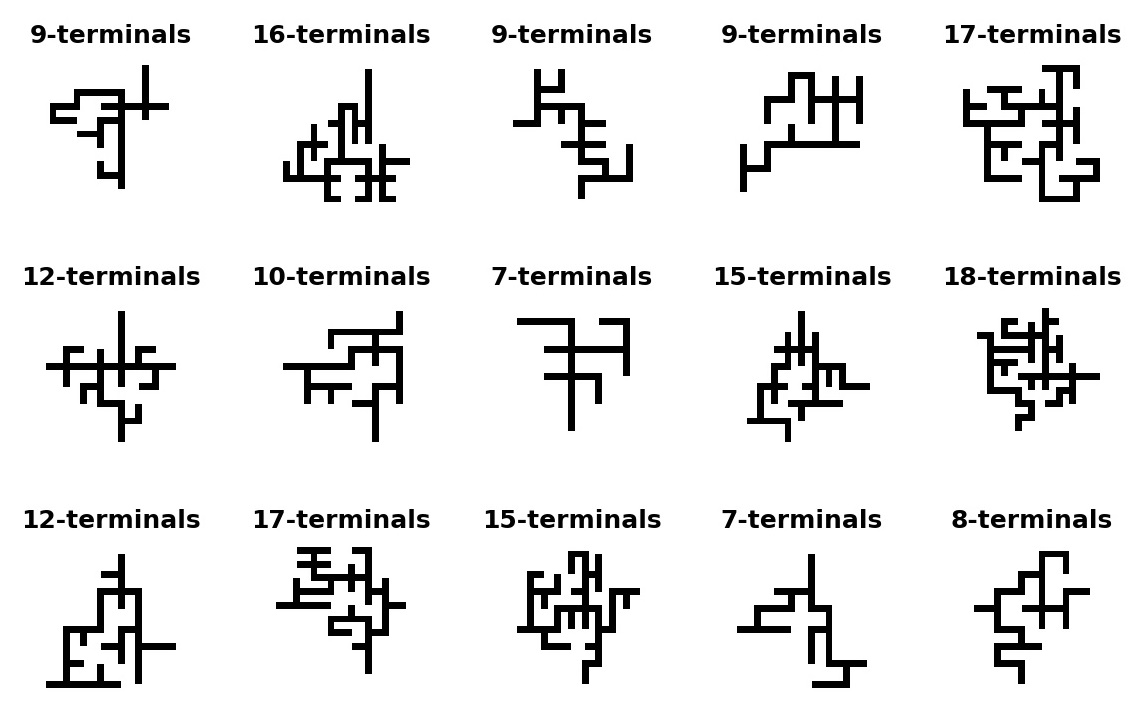
Preparing training and validation data sets¶
The archived data sets above contains half million rectilinear trees, which is too big for our first exercise. We will start with a small subset of 24000 training samples, 2000 samples from each group of 7-treminals, 8-terminals, ..., 18-terminals (12 groups). And a small validation set of 6000 samples (500 from each group). We have completely ignored rectilinear trees with less than 7 terminals, since there are not many of them and thus including them could turn our training set imbalanced. We therefor use class number 0 for trees with 7-terminals, class number 1 for trees with 8-terminals, etc...
Preparing such balanced subset requires that you iterate over the large data sets and pick the right number of trees for each type. Here are our training and validation sets:
so we suggest that you start with a smaller data sets first, and later increase their size if needed. You can create your own training and validation sets by applying utilities from the modules rectrees and imgutils.
Load training and test data¶
The imgutils module also contains a utility load_data for loading HDF5 files to memory (as Numpy arrays). This method accepts the names of your training and validation data set files, and it returns the following six Numpy arrays:
- X_train: an array of 24000 images whose shape is 24000x48x48.
- y_train: a one dimensional array of 24000 integers representing the class number of each image in X_train.
- Y_train: an 24000 array of one-hot vectors needed for Keras model. For more details see: http://stackoverflow.com/questions/29831489/numpy-1-hot-array
- X_test: an array of 6000 validation images (6000x48x48)
- y_test: validation class array
- Y_test: one-hot vectors for the validation samples
It should be noted that in addition to reading the images from the HDF5 file, the load_data method also performs some normalization of the image data like scaling it to a unit interval and centering it around the mean value. You can control these actions by additional optional arguments of this command. Please look at the source code to learn more.
X_train, y_train, Y_train, X_test, y_test, Y_test = load_data('train.h5', 'test.h5')
print('X_train shape:', X_train.shape)
print(X_train.shape[0], 'training samples')
print(X_test.shape[0], 'validation samples')
Let's also write two small utilities for drawing samples of images, so we can inspect our results visually.
def draw_image(img, id):
img = img.reshape(48,48)
plt.imshow(img, cmap='gray', interpolation='none')
plt.title("%d: %s" % (id, class_name[id]), fontsize=15, fontweight='bold', y=1.08)
plt.axis('off')
plt.show()
Let's draw image 18 in the X_train array as example
draw_image(X_train[18], y_train[18])

As we can see, the image is a bit blurry due to the normalization procedures that the load_data method has done to the original data. If you want to draw the raw data as it is in the HDF5 file, use the h5_get method to extract the raw image from the HDF5 file directly:
img = h5_get('train.h5', 'img_18')
id = y_train[18]
draw_image(img, id)

Sometimes we want to inspect a larger group of images in parallel, so we also provide a method for drawing a grid of consecutive images.
def draw_sample(X, y, n, rows=4, cols=4, imfile=None, fontsize=9):
for i in range(0, rows*cols):
plt.subplot(rows, cols, i+1)
img = X[n+i].reshape(48,48)
plt.imshow(img, cmap='gray', interpolation='none')
id = y[n+i]
plt.title("%d: %s" % (id, class_name[id]), fontsize=fontsize, y=1.08)
plt.axis('off')
plt.subplots_adjust(wspace=0.8, hspace=0.1)
draw_sample(X_train, y_train, 400, 3, 5)

Again, ignore the blurring images due to image normalization. The original images are pure black and white of course.
Counting terminals in RecTrees¶
Let's start with the terminals counting problem. Our aim is to build a neural network which accepts 48x48 grayscale image of a rectilinear tree and outputs the number of of terminals this tree has.
We start with a simple Keras model which combines one Convolution2D layer with two Dense layers. Although simple in terms of code, it is too expensive in terms of computation and hardware, as it contains 70 million parameters! This is way too much and should be avoided in general. However, we want to experiment with the common use of Dense layers and see why they are not good for image processing. In general, Dense layers should be avoided as much as possible when dealing with image data. The general practice is to use Convolution and Pooling layers. These two types of layers are explained in more detail in the following two articles, which we recommend to read before you approach the following code:
A Neural Network for counting terminals in RecTrees¶
Let's start with the terminals counting problem. Our aim is to build a nueral network which accepts 48x48 grayscale image of a rectilinear tree and outputs the number of of terminals this tree has.
We start with a simple Keras model which combines one Convolution2D layer and two Dense layers. Although simple in terms of code, it is too expensive in terms of computation and hardware, as it contains 70 million parameters! This is way too much and should be avoided in general. However, we want to experiment with the common use of Dense layers and see why they are not good for image processing. In general, Dense layers should be avoided as much as possible when dealing with image data. The general practice is to use Convolution and Pooling layers. These two types of layers are explained in more detail in the following two articles, which we recommend to read before you approach the following code:
Lets Train Model 1¶
We now define our first model for the recognizing the number of terminals in RecTrees. Note that unlike the common practice, we decided to use the SReLU activation method instead of the more popular relu activation. We did several test with relu but SReLU seems to be more appropriate for RecTrees. One of the amazing facts about SReLU is that it adapts itself during the learning process and not a constant function as other activations. You may read more about it in the following papers:
nb_epoch = 100
batch_size = 32
input_shape = X_train.shape[1:]
model = Sequential(name="model_1")
model.add(Convolution2D(64, 3, 3, input_shape=input_shape))
model.add(SReLU())
model.add(Flatten())
model.add(Dense(512))
model.add(SReLU())
model.add(Dropout(0.4))
model.add(Dense(256))
model.add(SReLU())
model.add(Dropout(0.4))
model.add(Dense(nb_classes))
model.add(Activation('softmax'))
print(model.summary())
save_model_summary(model, "model_1_summary.txt")
write_file("model_1.json", model.to_json())
fmon = FitMonitor(thresh=0.09, minacc=0.999, filename="model_1_autosave.h5")
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
hist = model.fit(
X_train,
Y_train,
batch_size=batch_size,
nb_epoch=nb_epoch,
shuffle=True,
validation_data=(X_test, Y_test),
verbose=0,
callbacks = [fmon]
)
model_file = "model_1.h5"
print("Saving model to:", model_file)
model.save(model_file)
plot(model, to_file="model_1_scheme.png", show_layer_names=False, show_shapes=True)
show_scores(model, hist, X_train, Y_train, X_test, Y_test)


loss, accuracy = model.evaluate(X_train, Y_train, verbose=0)
print("Training: accuracy = %f ; loss = %f" % (accuracy, loss))
loss, accuracy = model.evaluate(X_test, Y_test, verbose=0)
print("Validation: accuracy1 = %f ; loss1 = %f" % (accuracy, loss))
Although the training accuracy is quite high (99.9% !), the overall result is not good! The 12% gap with respect to the validation accuracy is an alarming indication of overfitting (which is also clearly noticeable from the accuracy and loss graphs above). Our model is successful on the training set only and is not as successful for any other data.
Inspecting the output¶
Befor we search for a new model, let's take a quick look on some of the cases that our model missed. It may give us clues on the strengths and weaknesses of NN models, and what we can expect from these artificial models.
The predict_classes method is helpful for getting a vector (y_pred) of the predicted classes of our model 1. We should compare y_pred to the expected true classes y_test in order to get the false cases:
y_pred = model.predict_classes(X_test)
true_preds = [(x,y) for (x,y,p) in zip(X_test, y_test, y_pred) if y == p]
false_preds = [(x,y,p) for (x,y,p) in zip(X_test, y_test, y_pred) if y != p]
print("Number of valid predictions: ", len(true_preds))
print("Number of invalid predictions:", len(false_preds))
The array false_preds consists of all triples (x,y,p) where x is an image, y is its true class, and p is the false predicted value of model.
Lets visualize a sample of 15 items:
for i,(x,y,p) in enumerate(false_preds[0:15]):
plt.subplot(3, 5, i+1)
img = x.reshape(48,48)
plt.imshow(img, cmap='gray')
plt.title("%d\ny: %s\np: %s" % (i, class_name[y], class_name[p]), fontsize=9, loc='left')
plt.axis('off')
plt.subplots_adjust(wspace=1.0, hspace=0.7)

Interestingly, in all the observed 15 cases, our model missed the correct answer by one terminal only, which is not so bad. Almost a human behavior (in fact when I try to count the number of terminals manualy, I sometimes miss by 2 or even by 3!)
Second Keras Model for the RecTrees database¶
Lets try to add an additional Convolution2D layer and reduce the width of the Dense layers. The number of parameters is still too high (32 millions), but much less than model 1.
nb_epoch = 100
batch_size = 32
input_shape = X_train.shape[1:]
model = Sequential(name="model_2")
model.add(Convolution2D(64, 3, 3, input_shape=input_shape))
model.add(SReLU())
model.add(Convolution2D(64, 3, 3, input_shape=input_shape))
model.add(SReLU())
model.add(Flatten())
model.add(Dense(256))
model.add(SReLU())
model.add(Dropout(0.4))
model.add(Dense(64))
model.add(SReLU())
model.add(Dropout(0.4))
model.add(Dense(nb_classes))
model.add(Activation('softmax'))
print(model.summary())
save_model_summary(model, "model_2_summary.txt")
write_file("model_2.json", model.to_json())
fmon = FitMonitor(thresh=0.09, minacc=0.999, filename="model_2_autosave.h5")
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
hist = model.fit(
X_train,
Y_train,
batch_size=batch_size,
nb_epoch=nb_epoch,
shuffle=True,
validation_data=(X_test, Y_test),
verbose=0,
callbacks = [fmon]
)
model_file = "model_2.h5"
print("Saving model to:", model_file)
model.save(model_file)
plot(model, to_file="model_2_scheme.png", show_layer_names=False, show_shapes=True)
show_scores(model, hist, X_train, Y_train, X_test, Y_test)


Seems like the second Convolution layer that we added has drastically reduced overfitting from over 12% to less than 2%! This is also clearly displayed in the accracy and loss graphs above. The two graphs are tightly closed. But of course there's still room for improvement.
Model 3¶
We will add a third Convolution layer, and increase the filter size to 5x5 in the first two layers. In adition, we add three new MaxPooling2D layers (one after each Convolution2D). The immediate effect of these layers is a drastic reduction in the model number of parameters from 90 million to 915K almost 1% compared to model 1. Even if we get similar results to model 1, it would be considered a success and a proof for why Convolution and Pooling layers are the right kind of layers to use for image data.
nb_epoch = 100
batch_size = 32
input_shape = X_train.shape[1:]
model = Sequential(name="model_3")
model.add(Convolution2D(64, 5, 5, input_shape=input_shape))
model.add(SReLU())
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Convolution2D(64, 5, 5, input_shape=input_shape))
model.add(SReLU())
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Convolution2D(64, 3, 3, input_shape=input_shape))
model.add(SReLU())
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(256))
model.add(SReLU())
model.add(Dropout(0.5))
model.add(Dense(128))
model.add(SReLU())
model.add(Dropout(0.5))
model.add(Dense(nb_classes))
model.add(Activation('softmax'))
print(model.summary())
save_model_summary(model, "model_3_summary.txt")
write_file("model_3.json", model.to_json())
fmon = FitMonitor(thresh=0.09, minacc=0.999, filename="model_3_autosave.h5")
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
hist = model.fit(
X_train,
Y_train,
batch_size=batch_size,
nb_epoch=nb_epoch,
shuffle=True,
validation_data=(X_test, Y_test),
verbose=0,
callbacks = [fmon]
)
model_file = "model_3.h5"
print("Saving model to:", model_file)
model.save(model_file)
plot(model, to_file="model_3_scheme.png", show_layer_names=False, show_shapes=True)
show_scores(model, hist, X_train, Y_train, X_test, Y_test)


loss, accuracy = model.evaluate(X_train, Y_train, verbose=0)
print("Training: accuracy = %f ; loss = %f" % (accuracy, loss))
loss, accuracy = model.evaluate(X_test, Y_test, verbose=0)
print("Validation: accuracy = %f ; loss = %f" % (accuracy, loss))
The training accuracy of model 3 is slightly smaller than in model 2 (by 0.7%) but there are two important factors that make model 3 much better than model 2:
- It is a significantly smaller model! only 900K parameters compared to 32 millions parameters in model 2. This is critical.
- The correlation between the accuracy and validation graphs is more tight (in spite of the occasional spikes).
With some more fine tuning, we believe that mode 3 can achieve greater accuracy and validation scores, without adding too many parameters. So it is better to invest extra efforts on model 3 rather than model 2 or 1.
We will stop our experiments here and let you try to do better (good luck ;-). Is it possible to achieve 100% accuracy??? And if so, in what cost? We don't want too many parameters (not a fare game!), and we don't want too many layers or too many nuerons. After all we are dealing with a rather simple image database (nice and clean geometrical figures), and we want to replace old school programmers with neural networks ... :-)
You may enlarge your training and validation sets. We used only 24000 training samples. How about using 48000 training samples (4000 per group)? You may also experiment with other activation functions and optimizers (there are plenty of them in Keras). You can also work directly in Theano or TensorFlow.
Before you proceed, lets take a look at some examples in which model 3 fails:
y_pred = model.predict_classes(X_test)
true_preds = [(x,y) for (x,y,p) in zip(X_test, y_test, y_pred) if y == p]
false_preds = [(x,y,p) for (x,y,p) in zip(X_test, y_test, y_pred) if y != p]
print("Number of valid predictions: ", len(true_preds))
print("Number of invalid predictions:", len(false_preds))
Let's draw the first 15 failures
for i,(x,y,p) in enumerate(false_preds[0:15]):
plt.subplot(3, 5, i+1)
img = x.reshape(48,48)
plt.imshow(img, cmap='gray')
plt.title("%d\ny: %s\np: %s" % (i, class_name[y], class_name[p]), fontsize=9, loc='left')
plt.axis('off')
plt.subplots_adjust(wspace=0.8, hspace=0.6)

Again, we see that our model sometimes misses one terminal. Is this the case for all other false predictions? That can be easily checked with the following one line of code
false_preds_2 = [(x,y,p) for (x,y,p) in zip(X_test, y_test, y_pred) if abs(y-p)>=2]
len(false_preds_2)
Yep! only 1 terminal missed in all false predictions. It means that a neural network solution is no erratic, and there is hope to close the gap with some additional effort.
Some more challenges¶
You can try counting the number of edges, number of vertices, or the number corners. You will need to generate balanced data sets for these projects (see above). A more interesting challenge would be: can a neural network identify the topological for of a rectilinear tree? The topological form of a given tree T is the "smallest" cannonical tree which is geometrically isomorphic to T. Here are a few examples of trees and their topological forms:
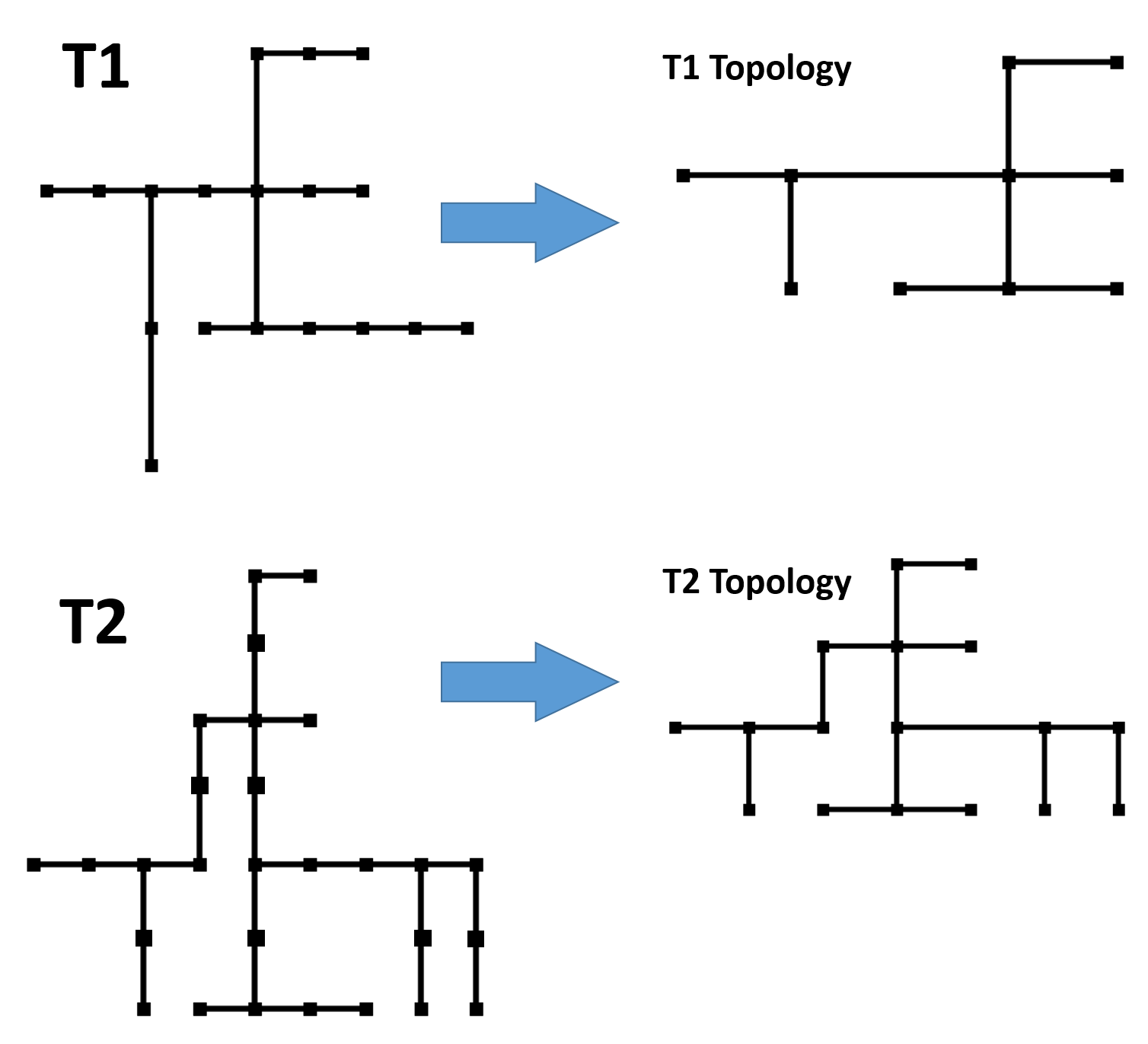
Each topology can be encoded by an integer, and our neural network accepts a 48x48 image of a rectilinear tree and needs to output the integer corresponding to its topology.
The main obstacle we expect in this challenge is creating a large balanced training data set. There are a lot of topologies, and we'll probably need hundreds or maybe thousands sample for each topology, which can make the training set too large. We could restrict ourselves to a small subset of topoloies though. You will also need to mine the half million trees data sets to get enough samples in a balanced state.
Other routing tree properties can be considered for creating similar deep learning challenges. Work in progress ...