Poker Hand Detection¶
Database Creatores:
Robert Cattral (cattral@gmail.com)
Franz Oppacher (oppacher@scs.carleton.ca)
Carleton University, Department of Computer Science
Intelligent Systems Research Unit
1125 Colonel By Drive, Ottawa, Ontario, Canada, K1S5B6
https://archive.ics.uci.edu/ml/datasets/Poker+Hand

The Poker Hand database consists of 1,025,010 instances of poker hands. Each instance is an example of a poker hand consisting of five cards drawn from a standard deck of 52 cards. Each card is described using two attributes (suit and rank), for a total of 10 features. There is one Class attribute that describes the Poker Hand. The order of cards is important, which is why there are 480 possible Royal Flush hands as compared to 4 (one for each suit explained in more detail below).
Feature Information¶
S1 - Suit of card 1
Ordinal (1-4) representing: Hearts=1, Spades=2, Diamonds=3, Clubs=4
1 heart ♥ 2 spade ♠ 3 diamond ♦ 4 club ♣
C1 - Rank of card 1
Numerical (1-13) representing: Ace=1, 2, 3, 4, 5, 6, 7, 8, 9, 10 , Jack=11, Queen=12, King=13S2 - Suit of card 2
Ordinal (1-4) representing: Hearts=1, Spades=2, Diamonds=3, Clubs=4C2 - Rank of card 2
Numerical (1-13) representing: Ace=1, 2, 3, 4, 5, 6, 7, 8, 9, 10 , Jack=11, Queen=12, King=13S3 - Suit of card 3
Ordinal (1-4) representing: Hearts=1, Spades=2, Diamonds=3, Clubs=4C3 - Rank of card 3
Numerical (1-13) representing: Ace=1, 2, 3, 4, 5, 6, 7, 8, 9, 10 , Jack=11, Queen=12, King=13S4 - Suit of card 4
Ordinal (1-4) representing: Hearts=1, Spades=2, Diamonds=3, Clubs=4C4 - Rank of card 4
Numerical (1-13) representing: Ace=1, 2, 3, 4, 5, 6, 7, 8, 9, 10 , Jack=11, Queen=12, King=13S5 - Suit of card 5
Ordinal (1-4) representing: Hearts=1, Spades=2, Diamonds=3, Clubs=4C5 - Rank of card 5
Numerical (1-13) representing: Ace=1, 2, 3, 4, 5, 6, 7, 8, 9, 10 , Jack=11, Queen=12, King=13CLASS Poker Hand Ordinal (0-9)
0 - Nothing in hand; not a recognized poker hand 1 - One pair; one pair of equal ranks within five cards 2 - Two pairs; two pairs of equal ranks within five cards 3 - Three of a kind; three equal ranks within five cards 4 - Straight; five cards, sequentially ranked with no gaps 5 - Flush; five cards with the same suit 6 - Full house; pair + different rank three of a kind 7 - Four of a kind; four equal ranks within five cards 8 - Straight flush; straight + flush 9 - Royal flush; {Ace, King, Queen, Jack, Ten} + flush
Example¶
The following poker hand will be represented in the database by the following 10 features vector
1, 1, 4, 1, 2, 10, 3, 7, 1, 3

Prerequisites¶
To run the code below you'll need to download following private libraries which we use in several examples of this course:
- http://www.samyzaf.com/ML/style-notebook.css
- http://www.samyzaf.com/cgi-bin/view_file.py?file=ML/lib/kerutils.py
- http://www.samyzaf.com/cgi-bin/view_file.py?file=ML/lib/dlutils.py
You may download all course code libraries from this github repository:
https://github.com/samyzaf/kerutils
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib import rcParams
rcParams['figure.figsize'] = 10,7
# Our deep learning library is Keras
from keras.models import Sequential
from keras.layers.core import Dense, Dropout
from keras.utils.np_utils import to_categorical
import numpy as np
# fixed random seed for reproducibility
np.random.seed(0)
# private libraies
from kerutils import *
%matplotlib inline
# These are css/html styles for good looking ipython notebooks
from IPython.core.display import HTML
css = open('style-notebook.css').read()
HTML('<style>{}</style>'.format(css))
features = ['S1', 'C1', 'S2', 'C2', 'S3', 'C3', 'S4', 'C4', 'S5', 'C5', 'CLASS']
data = pd.read_csv('data/poker-hand-training.csv', names=features)
# Lets view the first 10 rows of the data set
# See bellow what these names mean
data.head(10)
# How many rows do we have?
len(data.index)
# How many columns do we have?
len(data.columns)
# How many records do we have in our data set?
data.size # 11 * 25010
# You can get everything in one line !
data.shape
# View the last 10 records of our data set
data.tail(10)
# Some statistics to get acquainted with the data
nb_classes = 10 # we have 10 classes of poker hands
cls = {}
for i in range(nb_classes):
cls[i] = len(data[data.CLASS==i])
print(cls)
# Let's keep a map of poker hand class id to class name
poker_hands = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
hand_name = {
0: 'Nothing in hand',
1: 'One pair',
2: 'Two pairs',
3: 'Three of a kind',
4: 'Straight',
5: 'Flush',
6: 'Full house',
7: 'Four of a kind',
8: 'Straight flush',
9: 'Royal flush',
}
for i in poker_hands:
print("%s: %d" % (hand_name[i], cls[i]))
The classes are highly imbalanced, which could hamper the training process. Our deep learning model will learn a lot about "One Pair" (10599 hands) but very little about "Royal Flash" (only 5 hands) !?
It is usually a good practice to keep this in mind and draw a class distribution bar chart before you start building and training deep learning models. The bar chart will give you a thick visual clue regarding imbalance.
plt.bar(poker_hands, [cls[i] for i in poker_hands], align='center')
plt.xlabel('Poker hand id')
plt.ylabel('Number of instances')

Deep Learning with Keras¶
We now proceed to build a neural network using Keras for detecting the hand poker class from the 10 feature of the 5 cards at hand. We will first split our data to the first 10 predictive features and the last CLASS feature will be converted to a catogorical form. As usuall, Pandas DataFrames must be converted to Numpy matrices in order to be recognized by Keras.
# Let's first extract the first 10 features from our data (from the 11 we have)
# We want to be able to predict the class (hand poker type)
X_train = data.iloc[:,0:10].as_matrix()
y_train = data.iloc[:,10].as_matrix()
# let's look at the first 20 records sample
X_train[0:20]
y_train[0:20]
Keras Model Defintion¶
Let's start with a simple neural network that consists of
- An input layer of 10 neurons
- A hidden layer of 16 neurons
- An ouput layer of 10 neurons (one for each poker hand class)
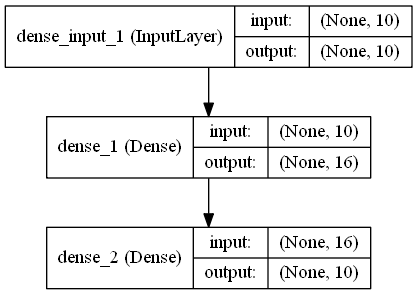
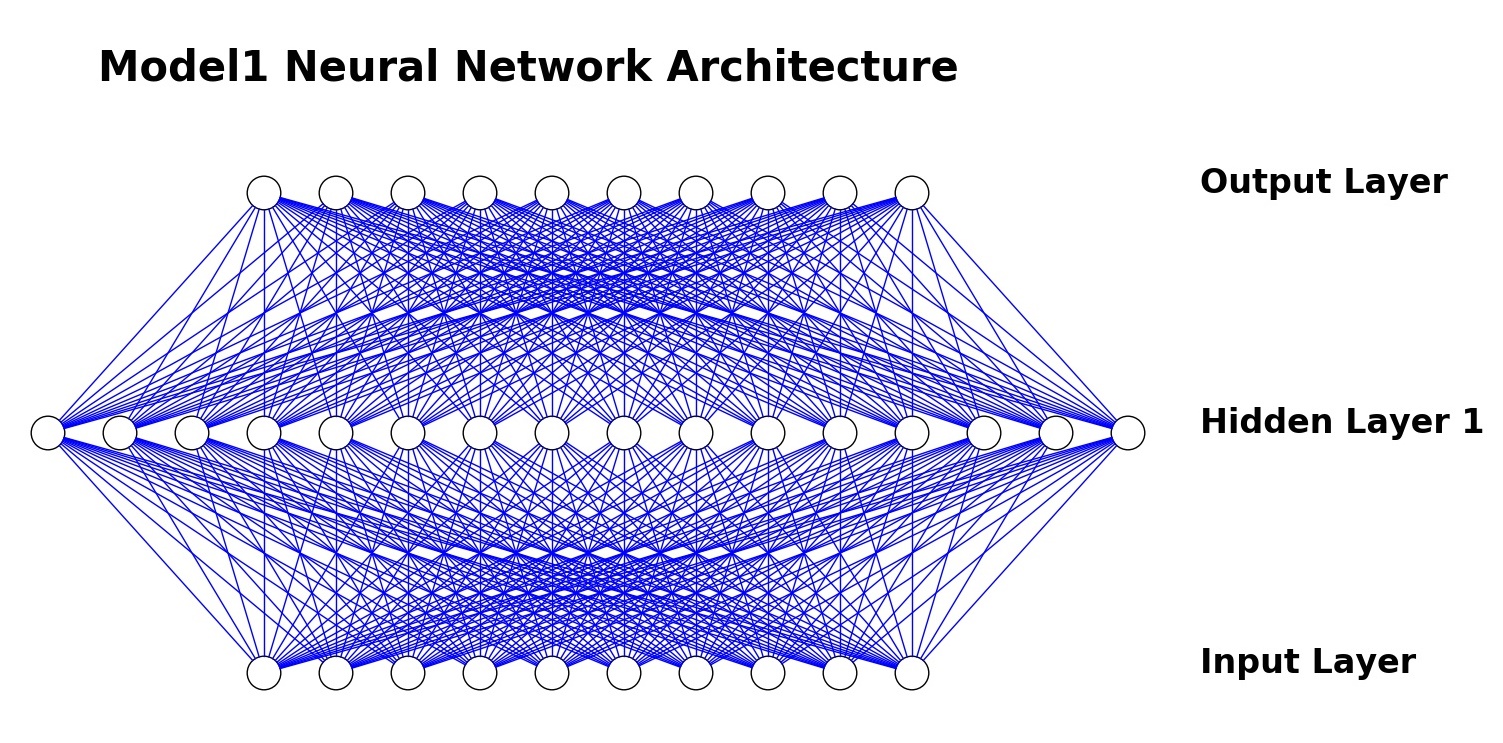
# Our first Keras Model
model1 = Sequential()
model1.add(Dense(16, input_shape=(10,), init='uniform', activation='relu'))
model1.add(Dense(10, init='uniform', activation='softmax'))
Compiling the model¶
model1.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
Training our Model¶
Keras training method (fit) expects one-hot binary vectors as class output. Hence Keras contains a special utility (to_categorical) for converting integer classes to one-hot binary vectors. One-hot form conversion looks like this:
0 -> [1, 0, 0, 0, 0, 0, 0, 0, 0, 0] 1 -> [0, 1, 0, 0, 0, 0, 0, 0, 0, 0] 2 -> [0, 0, 1, 0, 0, 0, 0, 0, 0, 0] etc.
Y_train = to_categorical(y_train)
We will use 300 epochs and a batch_size of 32. We also use our FitMonitor callback from our kerutils library (see above download links), which is a more compact progress monitor with intermediate summaries after each 10% period. The view_acc utility is useful for viewing the model training accuracy.
# We use our FitMonitor callback from our kerutils library (see above for download)
fmon = FitMonitor()
h = model1.fit(X_train, Y_train, nb_epoch=300, batch_size=32, verbose=0, callbacks=[fmon])
# h is a history object that records the fitting process
Training accuracy of 58.1% for the first attempt is not too bad. The accuracy graph suggests that adding more epochs will probably not going to take us to a better accuracy. It seems to be stuck around the 58% accuracy level.
view_acc(h)

# Validating the accuracy and loss of our training set
loss, accuracy = model1.evaluate(X_train, Y_train, verbose=0)
print("Train: accuracy=%f loss=%f" % (accuracy, loss))
Besides the training accuracy, there is also the test accuracy. Testing our model on the training data set is not a fair game. A good testing ground is a completely different set of samples which our model have not already seen. Our testing database consists of 1 milion new poker hands! Let's try them out and see if our model is successful in predicting their class, at least at the same accuracy level as 58% ...
features = ['S1', 'C1', 'S2', 'C2', 'S3', 'C3', 'S4', 'C4', 'S5', 'C5', 'CLASS']
tdata = pd.read_csv('data/poker-hand-testing.csv', names=features)
# Checking the success rate on our test set
X_test = tdata.iloc[:,0:10].as_matrix()
y_test = tdata.iloc[:,10].as_matrix()
Y_test = to_categorical(y_test)
loss, accuracy = model1.evaluate(X_test, Y_test, verbose=0)
print("Test: accuracy=%f loss=%f" % (accuracy, loss))
Test accuracy is 57.6% which is pretty close to the training accuracy (58.1%). This is an encouraging indication that our deep learning model is doing its work as expected. It has been trained on 25,000 samples and gave an exact prediction on a totally different 1 milion samples! This is quite good, so far.
Let's save this model, and proceed to the next one ...
model1.save('model1.h5')
We can get the predictions vectors of our test set in the following way:
y_pred = model1.predict_classes(X_test, verbose=0)
And then count the number of failures
np.count_nonzero(y_pred - y_test)
We have 423,973 false predictions. We can save them in a numpy array and analyze them
false_preds = [(x,y,p) for (x,y,p) in zip(X_test, y_test, y_pred) if y != p]
Just from looking at the first 20 false predictions we see that our model identified "One Pair" hands with "Nothing in hand", which are very close classes.
false_preds[0:20]
Second Keras Model¶
So instead of trying to improve model1 by adding more epochs or tuning activity and optimization, lets build a new model with one extra hidden layer and with more neurons at each layer
model2 = Sequential()
model2.add(Dense(50, input_shape=(10,), init='uniform', activation='relu'))
model2.add(Dense(50, init='uniform', activation='relu'))
model2.add(Dense(nb_classes, init='uniform', activation='softmax'))
model2.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
fmon = FitMonitor(thresh=0.03, minacc=0.99, filename="model1.h5")
h = model2.fit(
X_train,
Y_train,
batch_size=32,
nb_epoch=200,
shuffle=True,
verbose=0,
callbacks = [fmon]
)
show_scores(model2, h, X_train, Y_train, X_test, Y_test)


This is progressing pretty well: 97.3% accuracy level on our second simple neural network. The model accuracy graph suggests that we get higher accuracy by adding more epochs. Worth trying as an exercise.
Lets see if we get a similar precision rate on our large test set
loss, accuracy = model2.evaluate(X_test, Y_test, verbose=0)
print("Test: accuracy=%f loss=%f" % (accuracy, loss))
This is pretty close and is a strong indication to our model resiliency. Lets sample the false predictions and see what our model has missed:
y_pred = model2.predict_classes(X_test, verbose=1)
false_preds = [(x,y,p) for (x,y,p) in zip(X_test, y_test, y_pred) if y != p]
# How many false predictions do we have?
len(false_preds)
# Lets take a look at 20 samples
[(a[1], a[2]) for a in false_preds[0:20]]
We see that there are stiil mismatches between "one pair" and "Nothing at hand", but now we also see mismatches between "One pair" and "Two pairs", and more ... we can continue and check more samples, but you get the idea. Let's save this model, and proceed to the next one ...
model2.save("model2.h5")
Third Keras Model¶
We will use two hidden layers, with 400 neurons each, and run 500 epochs.
model3 = Sequential()
model3.add(Dense(200, input_shape=(10,), init='uniform', activation='relu'))
model3.add(Dense(400, init='uniform', activation='relu'))
model3.add(Dense(200, init='uniform', activation='relu'))
model3.add(Dense(nb_classes, init='uniform', activation='softmax'))
model3.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
fmon = FitMonitor(thresh=0.03, minacc=0.996, filename="model3.h5")
h = model3.fit(
X_train,
Y_train,
batch_size=32,
nb_epoch=100,
shuffle=True,
verbose=0,
callbacks = [fmon]
)
show_scores(model3, h, X_train, Y_train, X_test, Y_test)


# Validating the accuracy and loss of our test set
loss, accuracy = model3.evaluate(X_test, Y_test, verbose=0)
print("Test: accuracy=%f loss=%f" % (accuracy, loss))
Adding more neurons and one more hidden layer did help to get 98.7% accuracy level without really hard work from our part. All we did is guess a few numbers and parameters (very easy to do) and Keras wonderfully produced an efficient clean working model.
It took less that 20 minutes to build this network, and it potentially saves us one month programmer work (are we approaching the end of human programmers? ;-).
From the model accuracy graph it does not look like we can do better by running more epochs. Let's save this model, and proceed to the next one ...
model3.save("model3.h5")
Fourth Keras Model¶
This time we'll throw a lot of neuron on each layer. This is however not wise or desired in most cases. Large neural networks are prone to be slow and consume much more memory than small ones. This is however a matter of trade-offs and we're still experimenting. Sometimes high precision is worth the extra weight.
model4 = Sequential()
model4.add(Dense(400, input_shape=(10,), init='uniform', activation='relu'))
model4.add(Dense(800, init='uniform', activation='relu'))
model4.add(Dense(400, init='uniform', activation='relu'))
model4.add(Dense(nb_classes, init='uniform', activation='softmax'))
model4.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
fmon = FitMonitor(thresh=0.03, minacc=0.996, filename="model3.h5")
h = model4.fit(
X_train,
Y_train,
batch_size=32,
nb_epoch=200,
shuffle=True,
verbose=0,
callbacks = [fmon]
)
show_scores(model3, h, X_train, Y_train, X_test, Y_test)


# Validating the accuracy and loss of our test set
loss, accuracy = model4.evaluate(X_test, Y_test, verbose=0)
print("Test: accuracy=%f loss=%f" % (accuracy, loss))
Looks like our best achievment so far: 99.8% training accuracy and 99.6% validation accuracy.
Now that you've seen enough examples, you can get creative and try new models. Take into account that Keras offers plenty of activation functions, optimizers, and layer types that we haven't touched at all. So there are literally infinitely many combinations that you can try. As this is planned as a course unit, here is an idea for a project challenge which is also a kind of fun competition to try. I haven't tried it mysel though (I may be wrong with this ambition...), but be glad to see a neat solution if it exists.
Couse Project Challenge¶
Find a minimal neural network which adhers to the following requirements:
- Produces at least 99.99% accuracy on the training and testing data sets
- Number of deep layers does not exceed 8
- Number of nuerons at each layer does not exceed 200
- Number of training epochs does not exceed 10000
- You're not allowed to use any test sample for training! (not even one instance ;-)
- You will have to submit a full model definition from the ground up: layers, compilation, and training methods
The solution with the smallest number of neurons will receive the highest grade, and the remaining solutions will receive smaller grades relative to their ranking compared to the best solution.