NLP with gensim (word2vec)¶
Old outdated notebook. A new updated Google colab notebook in progress ...
NLP (Natural Language Processing) is a fast developing field of research in recent years, especially by Google, which depends on NLP technologies for managing its vast repositories of text contents.
In this study unit we will lay a simple introduction to this field through the use of
the excellent gensim Python package of
Radim Rehurek's
and his excellent word2vec Tutorial:
https://rare-technologies.com/word2vec-tutorial.
We have followed Radim's code with some supplements and more examples,
and adapted it to an IMDB movie reviews dataset
from Cornell university:
https://www.cs.cornell.edu/people/pabo/movie-review-data
You may downlaod this dataset more conveniently from here:
http://www.samyzaf.com/ML/nlp/aclImdb.zip
Load packages¶
# These are css/html style for good looking ipython notebooks
from IPython.core.display import HTML
css = open('c:/ml/style-notebook.css').read()
HTML('<style>{}</style>'.format(css))
# -*- coding: utf-8 -*-
import gensim
import logging
import os
import nltk.data
import string
%matplotlib inline
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
print ("PACKAGES LOADED")
The following class defined a Python generator which parses all files (recursively) in a given directory, and yields the sentences there one at a time (thus saving loads of memory).
class SentGen(object):
def __init__(self, dirname):
self.dirname = dirname
def __iter__(self):
for path,dirs,files in os.walk(self.dirname):
for fname in files:
for line in get_sentences(path + '/' + fname):
yield line.split()
def get_sentences(fname):
tokenizer = nltk.data.load('tokenizers/punkt/english.pickle')
fp = open(fname, 'r', encoding="utf-8")
data = fp.read()
fp.close()
trans_table = dict((ord(char), None) for char in string.punctuation)
sentences = nltk.sent_tokenize(data)
for sent in sentences:
yield sent.translate(trans_table)
Create an empty gensim model, no training yet¶
model = gensim.models.Word2Vec(iter=1, min_count=5)
Build a vocabulary¶
model.build_vocab(SentGen('aclImdb'), progress_per=200000)
Training the model¶
model.train(SentGen('aclImdb'), report_delay=8.0)
Model Saving¶
model.save('aclImdb.model')
Model Loading¶
Once a model was saved, it can be later loaded back to memory and trained with more sentences
# model = gensim.models.Word2Vec.load('model1')
# model.train(more_sentences)
Using the model¶
How many words does our model have? We simply need to check the size of our vocabulary with the Python len function:
len(model.wv.vocab)
Is the word 'women' in our vocabulary?
'women' in model.wv.vocab
Getting the list of all words in our vocabulary is easy. We can even sort them with the Python sorted function. We can also print and save them to a file.
words = sorted(model.wv.vocab.keys())
print("Number of words:", len(words))
# Save words to file: words.txt
fp = open("words.txt", "w", encoding="utf-8")
for word in words:
fp.write(word + '\n')
fp.close()
print (words[1500:1550]) # print 50 words from 1550 to 1549
Word similarity¶
One of the methods for checking model quality is to check if it reports high level of similarity between two semantically (or syntactically) equivalent words. Semantically similar words are expected to be near each other within our vector space. The gensim model.similarity methid is checking this sort of proximity and returns a real number from 0 to 1 that measures the amount of proximity.
However, keep in mind that our text corpus is relatively small (340MB text size with only 75K words), so our vector space is not expected to be fully adequate.
model.similarity('woman', 'man')
model.similarity('cat', 'dog')
model.similarity('paris', 'train') # low similarity
model.similarity('king', 'prince')
model.similarity('king', 'queen')
Unmatching word game¶
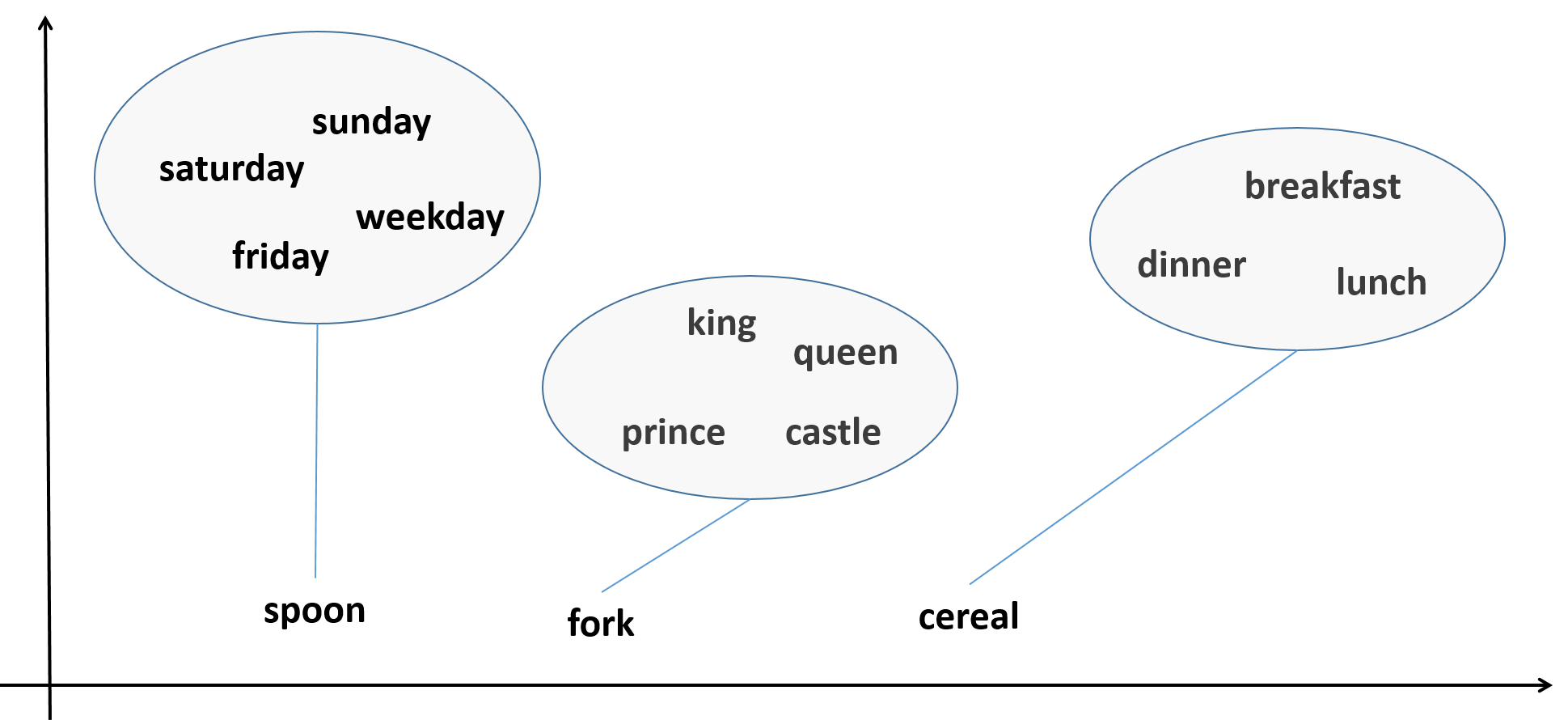
Another way to test if our word2vec model faithfully reflects our text corpus structure, is to check if it can separate a group of words to subgroups of related words. The gensim doesnt_match method accepts a group of words and reports which word in the group does not match the other words. A few examples can explain this better:
def get_unmatching_word(words):
for word in words:
if not word in model.wv.vocab:
print("Word is not in vocabulary:", word)
return None
return model.wv.doesnt_match(words)
get_unmatching_word(['breakfast', 'cereal', 'dinner', 'lunch'])
get_unmatching_word(['saturday', 'sunday', 'friday', 'spoon', 'weekday'])
get_unmatching_word(['king', 'queen', 'prince', 'fork', 'castle'])
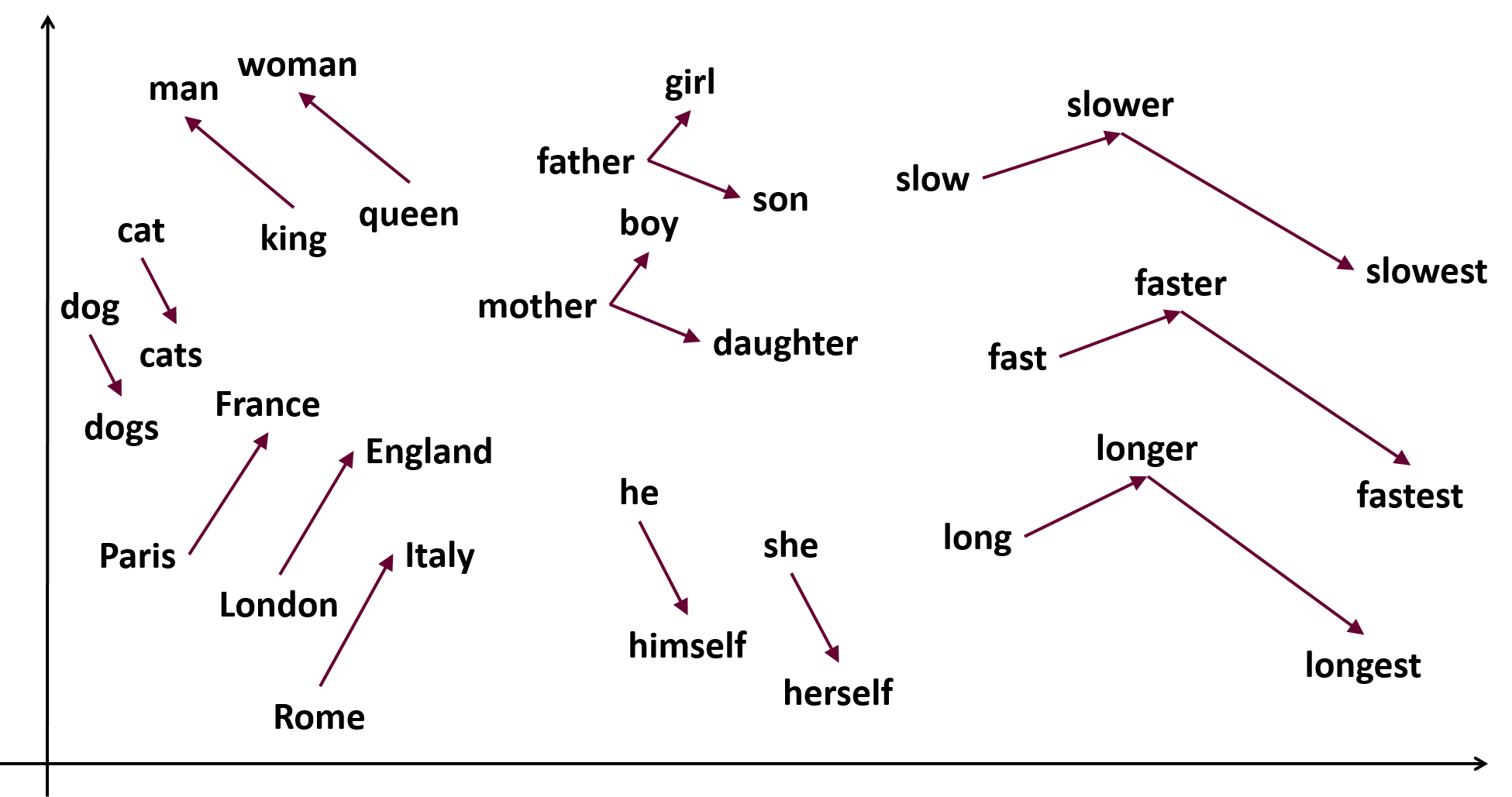
Semantic Relations in Vector Space¶
# The word 'woman' comes out 6th as the most similar
model.most_similar(positive=['king', 'man'], negative=['queen'], topn=6)
# The word 'higher' comes out 1st as the most similar, but also nottice the other words ...
model.most_similar(positive=['low', 'lower'], negative=['high'], topn=10)
# The word 'England' comes out 5th as the most similar
model.most_similar(positive=['Paris', 'France'], negative=['London'], topn=10)
# The word 'Italy' comes out 1st as the most similar
model.most_similar(positive=['Paris', 'France'], negative=['Rome'], topn=10)
# The word 'daughter' comes out 3rd as the most similar
model.most_similar(positive=['father', 'son'], negative=['mother'], topn=10)
# The word 'boy' comes out 1st as the most similar
model.most_similar(positive=['father', 'girl'], negative=['mother'], topn=10)
# The word 'cats' comes out 8th as the most similar (still, out of 75000 words ...)
model.most_similar(positive=['dog', 'dogs'], negative=['cat'], topn=10)
The significance of these similarities is that the word2vec embedding is somehow reflecting the semantical and syntactical structure of the text corpus. In this case we have less than 76K words, our text corpus is not large enough, and our vectors are too short: only 100 components (according to research you'll need between 300 to 500 long vectors to start getting accurate results). So this kind of similarities are a bit loose in our IMDB test case (many analogous words are missing or occuring only a small number of times in the texts). You can find in the web much larger text corpuses with millions of words in which this sort of vector algebra is highly matching the syntactical structure more closely.
Accessing the vectors¶
If you need to access the vector representation of word like 'king', this is very simple in gensim. The model object can be simply indexed with any word in the vocabulary:
print(model['king'])
print(model['king'].size) # vector size
You can also perform some vector algebra for checking all kinds of relations between words
d = (model['king'] - model['man']) - (model['queen'] - model['woman'])
np.sqrt(np.mean(d**2))
d = (model['king'] - model['man']) - (model['cat'] - model['desk'])
np.sqrt(np.mean(d**2))
d = (model['he'] - model['his']) - (model['she'] - model['her'])
np.sqrt(np.mean(d**2))
d = (model['he'] - model['his']) - (model['dog'] - model['cat'])
np.sqrt(np.mean(d**2))
d = (model['good'] - model['bad']) - (model['strong'] - model['weak'])
np.sqrt(np.mean(d**2))
d = (model['good'] - model['bad']) - (model['strong'] - model['small'])
np.sqrt(np.mean(d**2))